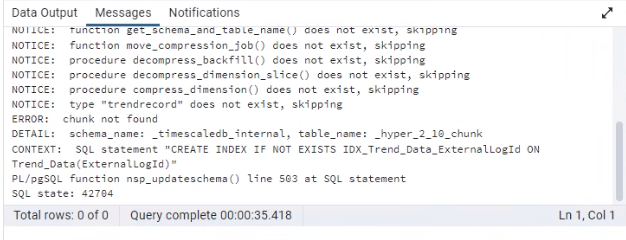
During schema upgrade, we get the following error.
ERROR: chunk not found
It’s a standalone server which only uses hypertables. We don’t use multinode or continous aggregates.
Any idea why we get this, and how to fix it?
During schema upgrade, we get the following error.
ERROR: chunk not found
It’s a standalone server which only uses hypertables. We don’t use multinode or continous aggregates.
Any idea why we get this, and how to fix it?
Hi @benneharli, I’m sorry for such a bad experience. I can imagine how frustrating it can be to lose a chunk.
What timescaledb and Postgresql version are you running? and what version you’re upgrading to?
Is it like production? any chance to try to reproduce it again?
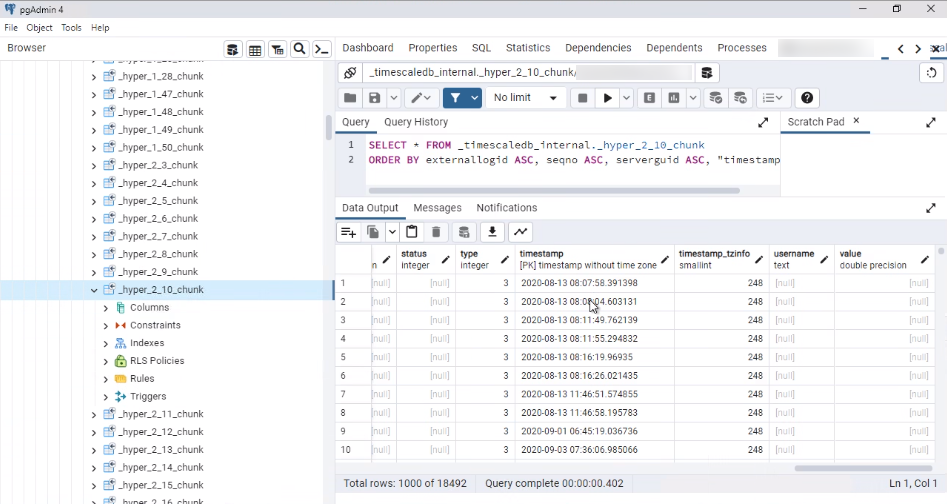
I see the DETAIL says _hyper_2_10_chunk. Have you tried to check what hypertable this chunk belongs to?
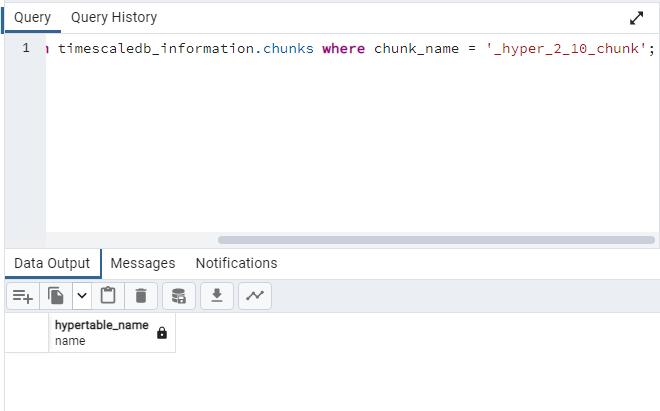
select hypertable_name
from timescaledb_information.chunks
where chunk_name = '_hyper_2_10_chunk';
Actually the main issue is not the lost chunk, but how we can get “over” it. It’s a schema upgrade we’re doing, not a server/database upgrade. Part of the schema upgrade is creating an index, and that’s where we get the error.
So, the chunk is definitely not there. How do I remove the reference to it?
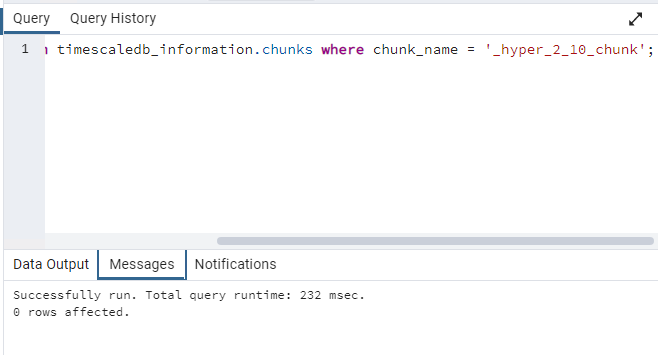
Anyone having any idea on how to proceed?
Thanks @jonatasdp but we’re not using compression, so it seems it doesn’t apply?
So it’s definitely not it, because the first query doesn’t return anything.
The chunk is there, and there’s data. See screen shot. It’s fine to delete the chunk as the data in the chunk is not used. Can that be done?
Can I just right click the _hyper_2_10_chunk and delete/drop it?
@jonatasdp any idea on this?
Sorry for the late reply, I was in a conference previous week! I’d suggest you open an issue in the extension repository and check if someone there can help to fix it. I know it’s not easy to reproduce the issue but more details you have easy is for the team to help you.
Thanks @jonatasdp , you mean here? Issues · timescale/timescaledb · GitHub
Yes! Exactly. Sorry for not putting the link.
Hey Ben, are you using latest version of Timescaledb? If not, what version?
The server came up from PG 11.6 and TS 1.7.2 to PG 13 and TS 2.9.3. I’m pretty sure it was bad before the upgrade.
In any case, I ended up running the following query, and simply executing the output of the query. That dropped all the orphaned tables, and we were able to apply the schema upgrade.
select ‘drop table _timescaledb_internal.’ || tablename || ‘;’ from pg_tables
where tablename like ‘_hyper_%_%_chunk’
and tablename not in
(
select chunk_name from timescaledb_information.chunks
);
Awesome! Thanks for sharing! I’ll see if we can also add this information to our official docs if more people want to migrate from this very old versions.