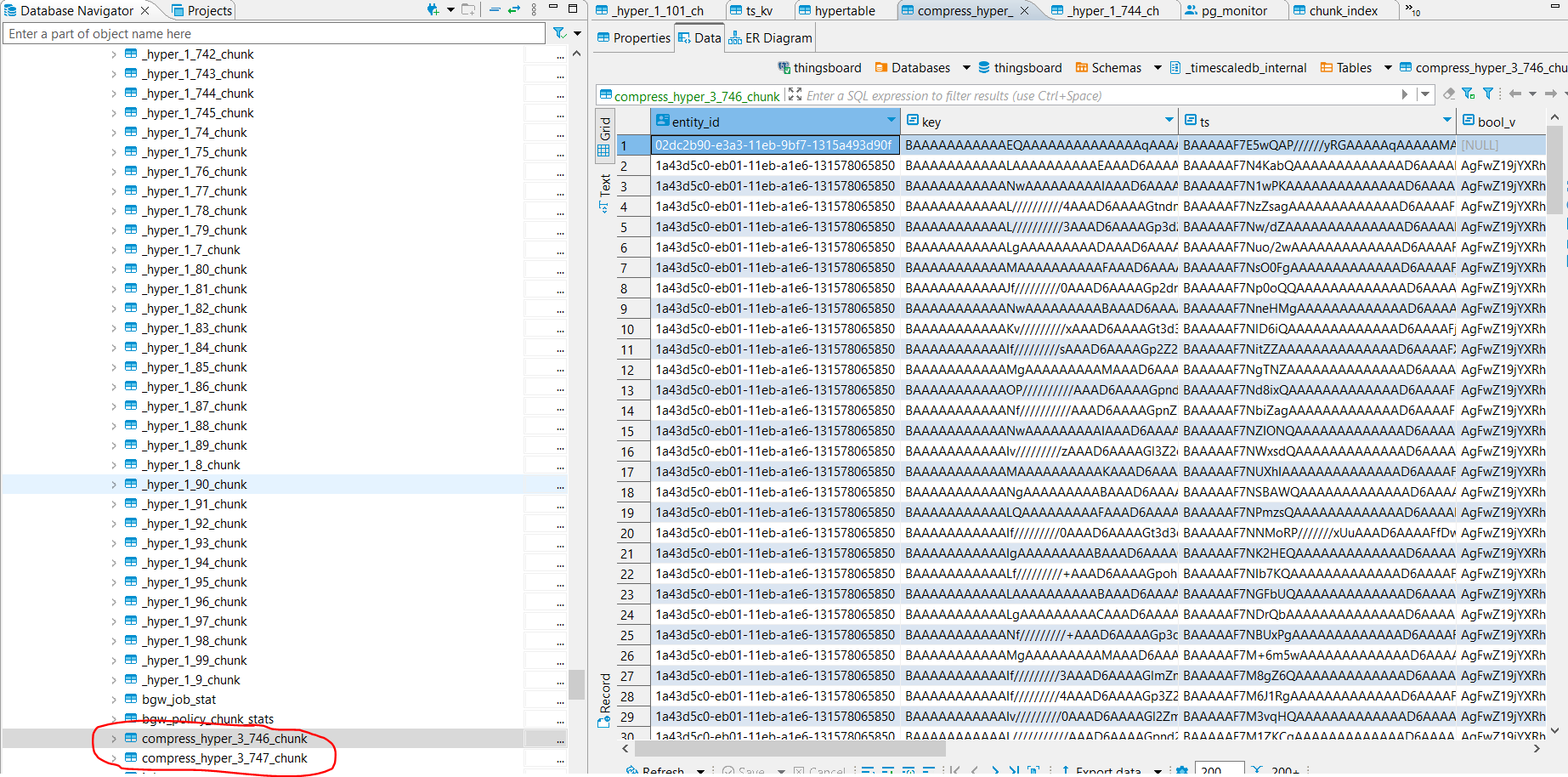
I have enabled compression in my Timescale Hypertable in order to compress manually some old chunks. As you can see in the picture there are only to compressed tables:
SELECT * FROM hypertable_compression_stats(‘public.ts_kv’);
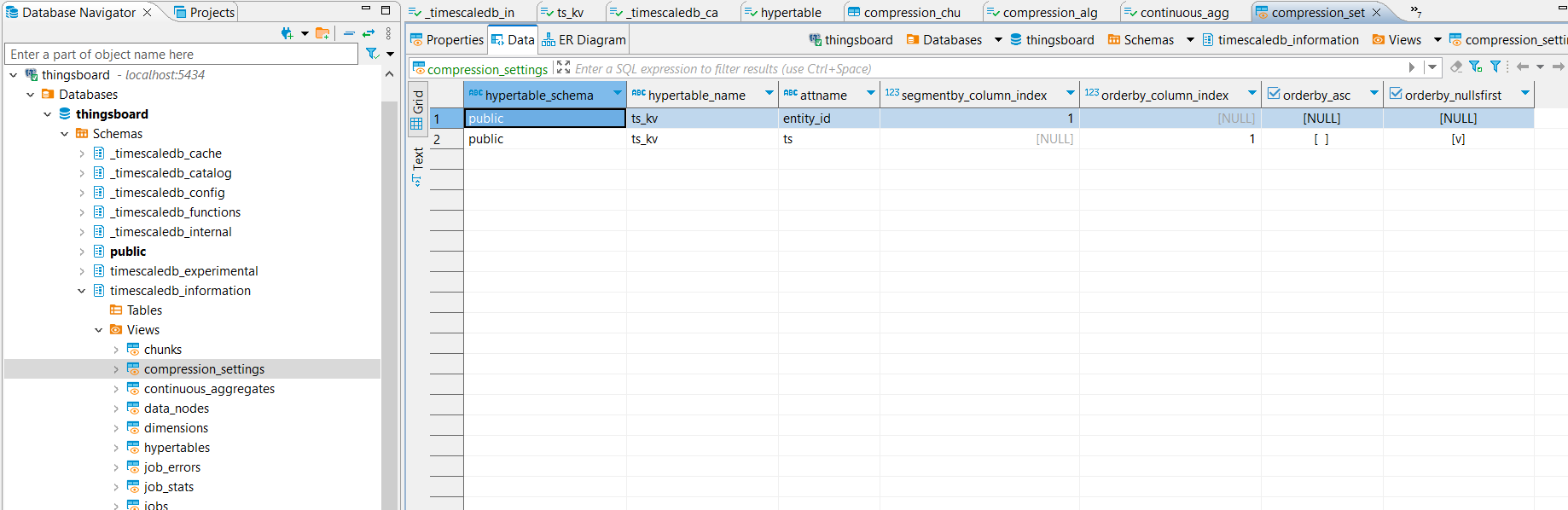
Hi @ingegaizka , can you check what you have in the view timescaledb_information.compression_settings.
Do you have a single hypertable? maybe it’s related to another hypertable.
If you think it’s a bug, let’s try to isolate the case and create a new database, create the extension, then a hypertable and follow your steps. If you get it in a reproducible manner, it would worth to report as an issue on github.
I have got a single hypertable which is automatically divide in chunks depending on the ts (timestamp). But, it is true that in this view seems to be another kind of mechanism apply…
I do not know if it is a bug but, I have been using this database for 2 years and it has got a hundreds of GB of information. I think creating a new database is a problematic option.
Might it be related with compression_settings view’s info?
Hello, @ingegaizka !
For each chunk that is compressed it is created compressed sub chunk. If you run show_chunks(‘your_hypertable_name’) then you will see only names of main chunks. But when you run explain plan of query then you will see compressed subchunks.
Don`t worry about that and use the tsdb calmly)
Hello @LuxCore !
Thank you for your response. But, there is something that I do not understand. I have got a process to check the augmentation of database size every day and it was usually of 300 MB. Now, after enabled compression (not activated to compress automatically) in Timescaled it is less than 1 MB. It meas that the current data is compressing directly when it is injected but, it was not what I want neither what I configured.
What do you mean with reproducible steps? I enabled compression for the hypertable and, then, I manually compressed 2 old chunks. Not more. It was the only thing I did.