

Implementing Filtered Semantic Search Using Pgvector and JavaScript
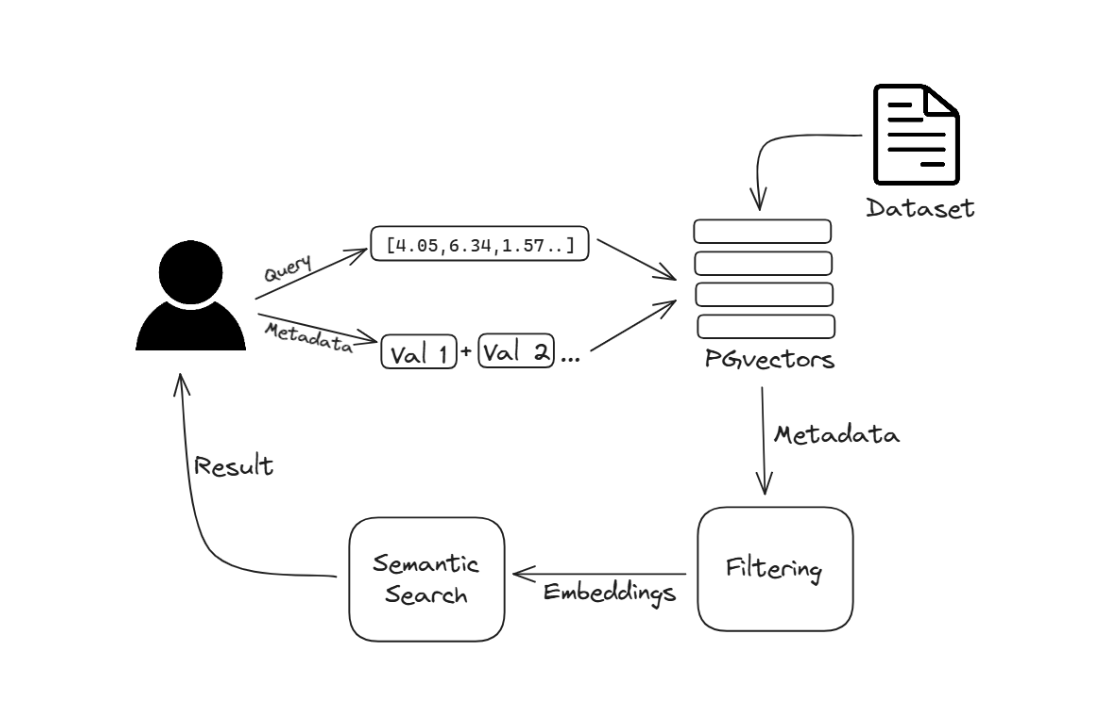
Conventional search methods rely on keyword matching, where the system locates exact words or phrases from the query within documents. This technique can be enhanced to better capture the context and intent behind the user's query, leading to more relevant and precise search results. Semantic search focuses on understanding the meaning and intent behind the query. Combining semantic search with filters—or additional parameters to narrow the results based on specific attributes—further improves accuracy.
In this article, we explore semantic search with filters and demonstrate how you can implement it using pgvector and JavaScript.
How Does Semantic Search Work?
Semantic search systems leverage vector embeddings, which are numerical representations of words and phrases generated by AI models. These embeddings capture the semantic relationships between words by placing them in a high-dimensional space where similar meanings are closer together.
For example, in vector similarity, the words "Jupiter" and "Saturn" will have vectors close to each other due to their related meaning as planets. This proximity enables a semantic search system to understand that a query about "planets" should include results for both "Jupiter" and "Saturn," even if there is no exact keyword match.
Semantic search has multiple applications:
- E-commerce search: in e-commerce, semantic search improves product search by understanding user intent, leading to more accurate product recommendations.
- Content recommendation and discovery: for content discovery, it enables users to find relevant articles, videos, or documents even if their queries don't match the exact keywords.
- Knowledge management: in knowledge management, semantic search enhances the retrieval of information by understanding the context, making it easier to find precise answers to complex queries.
- RAG systems: retrieval-augmented generation (RAG) systems leverage semantic search to find documents relevant to a user’s query, then prompt large language models (LLMs) with those documents to construct a response.
- Reverse image search: when images are converted to vectors, semantic search can help create reverse image search engines, allowing the system to find similar images based on a query image.
The Role of Filters in Semantic Search
In semantic search systems, data is typically converted into vector embeddings and stored in a vector store along with their metadata. For instance, in the case of a document, the metadata could include attributes such as the document’s title, author, publication date, and category. This metadata not only helps provide additional context but can also be used to narrow down search results by using filters.
Filters enhance the precision and relevance of semantic search by helping you refine the search results. For example, when searching for recent research papers on a specific topic, you can apply a date filter to exclude older publications.

Filters can be of different types:
- Time filters: allow you to restrict search results to a specific timeframe
- Categorical filters: enable you to narrow down results based on categories or tags
- Numerical filters: help you apply numerical ranges to filter results, thereby obtaining results that fall within specific quantitative criteria
- Geospatial filters: narrow your search results using latitude and longitude
When using filters, you can combine multiple conditions using logical operators (AND, OR, NOT) to refine your search results even further and achieve precise outcomes.
Semantic Search and PostgreSQL
In Stack Overflow’s 2023 Developer Survey, PostgreSQL emerged as the number one database. DB-Engines.com also named it the DBMS of the Year 2023. PostgreSQL is not just a relational database; it boasts extremely powerful similarity search capabilities. Given its widespread use, PostgreSQL is an ideal choice for building AI applications.
To transform PostgreSQL into a fully-featured and high-performance vector store, you need the open-source extensions pgvector, pgai, and pgvectorscale.
Pgvector
Pgvector is an extension that adds vector store capabilities to PostgreSQL, integrating vector operations directly into SQL queries. It enables efficient similarity searches and high-dimensional data handling at scale, enhancing PostgreSQL to handle tasks like similarity search, clustering, and more. Learn more about pgvector.
Pgai
Pgai is an open-source PostgreSQL extension that integrates machine learning workflows within PostgreSQL. Working in tandem with pgvector, it allows you to create vector embeddings from your data, retrieve LLM chat completions, and reason over your data directly within PostgreSQL using SQL queries. You can explore pgai’s capabilities here.
Pgvectorscale
Pgvectorscale is an open-source PostgreSQL extension that enhances pgvector by introducing a new index type called StreamingDiskANN and a compression method known as Statistical Binary Quantization. Written in Rust, it improves the performance of pgvector through advanced indexing and compression techniques, enabling more efficient handling of large-scale vector data. You can read more about pgvectorscale here.
By using these three open-source extensions, you can transform PostgreSQL into a powerful tool for vector handling and building machine learning applications.
Filtered Similarity Search With Pgvectorscale’s StreamingDiskANN
One key feature of pgvectorscale is the StreamingDiskANN indexing algorithm. Originally inspired by research at Microsoft and later improved by Timescale researchers, the algorithm overcomes two critical limitations of HNSW (hierarchical navigable small world) indexes: scalability and cost.
In-memory HNSW indexes are commonly used in vector databases for similarity searches. However, as vector data grows, storing all data in memory becomes prohibitively expensive. StreamingDiskANN addresses this by storing part of the index on disk, making it more cost-efficient for large vector workloads. Since SSDs are cheaper than RAM, the StreamingDiskANN index reduces the cost of similarity searches over large volumes of vector data without sacrificing accuracy or performance.
As benchmarks show, on a dataset of 50 million Cohere embeddings (768 dimensions each), PostgreSQL with pgvector and pgvectorscale achieves 28x lower p95 latency and 16x higher query throughput compared to Pinecone's storage-optimized (s1) index for approximate nearest neighbor (ANN) queries at 99 % recall, all at 75 % less cost when self-hosted on AWS EC2.
Therefore, PostgreSQL with pgvector and pgvectorscale forms one of the most powerful approaches for building applications that leverage filtered similarity search algorithms.
Implementing Filtered Semantic Search With pgvector and Javascript/Typescript
Next, we will showcase how to build filtered semantic search with pgvector and Javascript/Typescript. If you are using Node.js in your stack, this method will help you harness semantic search into your application.
Prerequisites
Before we begin, make sure that you have Node.js installed. If not, you can install it using the steps found here.
You will also need a working setup of PostgreSQL, pgvector, and pgvectorscale.
Installing PostgreSQL, pgvector, and pgvectorscale
You will need a working PostgreSQL installation with pgvector and pgvectorscale extension. You can do this by installing the latest version of PostgreSQL, pgvectorscale, and TimescaleDB using a pre-built Docker image. You can also simply use Timescale Cloud, which already has pgvector, pgai, and pgvectorscale installed on top of a mature PostgreSQL cloud platform.
Once you’ve got a working PostgreSQL with pgvector and pgvectorscale, the next step is to connect to the database…
psql -d "postgres://<username>:<password>@<host>:<port>/<database-name>"
…and then enable the pgvectorscale extension:
CREATE EXTENSION IF NOT EXISTS vectorscale CASCADE;
The CASCADE automatically installs pgvector. Refer to this for other methods of installation.
You can also enable pgai, which we’ll use later to automate the process of embedding generation.
CREATE EXTENSION IF NOT EXISTS pgai;
Once done, you can verify whether or not the extensions have been installed:

Installing Javascript/Typescript packages
As part of this setup, we will also need to install a few node modules. Before installing, let’s initialize a package.json.
npm init -y{
"name": "with_js",
"version": "1.0.0",
"main": "index.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"keywords": [],
"author": "",
"license": "ISC",
"description": ""
}We will use the sequelize module to work with PostgreSQL. Sequelize is a popular ORM for Node.js.
npm install sequelize pg pg-hstoreWe can now proceed with implementing filtered semantic search using Javascript/Typescript.
Step 1: Connect to PostgreSQL and create table
Create a file named app.js.
const { Sequelize, DataTypes } = require('sequelize');
const sequelize = new Sequelize('postgres', 'postgres', 'password', {
host: 'localhost',
dialect: 'postgres',
});
const VectorModel = sequelize.define('document_embedding', {
id: {
type: DataTypes.INTEGER,
primaryKey: true,
autoIncrement: true,
},
metadata: {
type: DataTypes.JSONB,
allowNull: false,
},
content: {
type: DataTypes.TEXT,
allowNull: false,
},
}, {
tableName: 'document_embedding',
timestamps: true, // createdAt and updatedAt columns
});
// verify that table exists
async function ensureTableExists() {
try {
await VectorModel.sync({ alter: true });
console.log('Table has been created or altered successfully.');
} catch (error) {
console.error('Error ensuring table exists:', error);
}
}
This code creates a table with the columns id, metadata, and content. Since we have used timestamps:true, it will also create the columns createdAt and updatedAt.
Step 2: Populate the table
You can now populate the table. To demonstrate, we will use a CSV file that contains text content with metadata. For this example, we’ve used a multilingual customer tickets dataset from Kaggle.
First, install csv-parser and fs (for file system operations).
npm install csv-parser
npm install fs
Next, update the file app.js.
const fs = require('fs');
const csv = require('csv-parser');
async function insertDataFromCSV(filePath) {
const results = [];
fs.createReadStream(filePath)
.pipe(csv())
.on('data', (data) => results.push(data))
.on('end', async () => {
for (const row of results) {
if (!row.text) {
console.error('Error: content (text) field is null or undefined in row:', row);
continue;
}
const metadata = {
queue: row.queue,
priority: row.priority,
language: row.language,
subcategory: row.subcategory,
subject: row.subject
};
try {
await VectorModel.create({
metadata: metadata,
content: row.text,
});
} catch (error) {
console.error('Error inserting row:', row, error);
}
}
console.log('Data inserted successfully');
});
}
async function main() {
await ensureTableExists();
await insertDataFromCSV('path_to_data.csv');
}
main();
In the above function, the text field from the CSV file has been stored in the content column. The rest of the fields have been treated as metadata, such as queue, priority, language, subcategory, subject, and inserted into the metadata column of the table.
You can run the script using:
node app.js
You will need to modify the above function based on the structure of your data.
Step 3: Inspect the table (optional)
You can now inspect the first five rows of your table by using the following function.
async function displayFirstFiveRows() {
try {
const rows = await VectorModel.findAll({
limit: 5
});
console.log('First 5 rows:');
rows.forEach(row => {
console.log(row.toJSON());
});
} catch (error) {
console.error('Error fetching data:', error);
}
}
displayFirstFiveRows();
With our dataset, this is the first row:
{
id: 1,
metadata: {
queue: 'ACCOUNTING',
subject: 'Inquiry About Payment Method Update',
language: 'EN',
priority: 'MEDIUM',
subcategory: 'Customer Inquiries::Payments'
},
content: 'Dear Support Team,\n' +
'\n' +
'I would like to update the payment method linked to my account. I recently encountered an issue with my current payment method and would prefer to switch to a different one. Additionally, I have an outstanding invoice for which I need an updated version reflecting the new payment details.\n' +
'\n' +
'Thank you for your prompt assistance.\n' +
'\n' +
'Best regards,\n' +
'Anthony Weber, Cust# 53212',
createdAt: 2024-07-24T13:27:34.854Z,
updatedAt: 2024-07-24T13:27:34.854Z
}
Step 4: Generate embeddings using pgai
You can, of course, use Transformers.js to generate embeddings and populate the table with an embedding column in the previous step.
However, in this tutorial, we will use pgai, which allows us to generate embeddings using a specified model directly within PostgreSQL.
1. Set up pgai with OpenAI API key
To do this, we first need an OpenAI API key. Once you have acquired it, set it as an environment variable.
export OPENAI_API_KEY="my-super-secret-openai-api-key"Now, when you connect to your database, set it as a session-level parameter.
PGOPTIONS="-c ai.openai_api_key=$OPENAI_API_KEY" psql -d "postgres://<username>:<password>@<host>:<port>/<database-name>"
The ai.openai_api_key has been set for the duration of your psql session. You can now verify that pgai functions are working.
SELECT *
FROM openai_list_models()
ORDER BY created DESC
;Running this should produce a list with 32 rows that looks something like this:

2. Generate embeddings using pgai
We should now alter the table to add an embeddings column of VECTOR type. This is where the generated embeddings will be stored. You can add this column by using the following in your psql shell:
ALTER TABLE document_embedding ADD COLUMN embedding VECTOR(1536);
Now, you can use the following query to generate embeddings from the content column using the openai_embed function in pgai. Change the embedding model according to your preference.
update document_embedding set embeddi002'ng = openai_embed('text-embedding-ada-, format('%s', content));
Once this query completes, you can inspect your table to check whether or not the embeddings column now has vector embeddings.
SELECT * FROM document_embedding LIMIT 1;
You can use pgai to set up a background job in the database that automatically generates embeddings from data as it is inserted. You can also read more about it here.
3. Set up DiskANN index
You can use a StreamingDiskANN index to speed up the search. You can do this simply by:
CREATE INDEX document_embedding_idx ON document_embedding USING diskann (embedding);With that, we are now all set to test filtered semantic search on our data.
Step 5: Filtered semantic search using Javascript/Typescript
To showcase filtered semantic search, we will generate embeddings from a text and find other vectors that are semantically similar. We will also restrict the search by filtering on the priority field of the metadata.
Here’s how you can do it:
require('dotenv').config();
const OPENAI_API_KEY = process.env.OPENAI_API_KEY;
async function performFilteredVectorSearch(text, metadataFilter) {
try {
// Generate embedding using the provided SQL query with API key
const [embeddingResult] = await sequelize.query(
`SELECT openai_embed('text-embedding-ada-002', :text, _api_key => :apiKey);`,
{
replacements: { text: text, apiKey: OPENAI_API_KEY },
type: sequelize.QueryTypes.SELECT,
}
);
const queryEmbedding = embeddingResult.openai_embed;
// Format the vector data so that it can be used for the query
const queryEmbeddingString = `[${queryEmbedding.join(',')}]`;
// Define a similarity threshold and limit the results
const similarityThreshold = 0.7;
const limit = 5;
// Perform the filtered vector search using a raw SQL query
const results = await sequelize.query(
`
SELECT *
FROM document_embedding
WHERE embedding <-> :queryEmbedding < :similarityThreshold
AND metadata @> :metadataFilter
ORDER BY embedding <-> :queryEmbedding
LIMIT :limit
`,
{
replacements: {
queryEmbedding: queryEmbeddingString,
similarityThreshold,
metadataFilter: JSON.stringify(metadataFilter),
limit,
},
type: sequelize.QueryTypes.SELECT,
}
);
console.log('Filtered Vector Search Results:', results);
return results;
} catch (error) {
console.error('Error performing filtered vector search:', error);
} finally {
await sequelize.close();
}
}
// Example usage with a text and metadata filter
const text = 'your similarity search text';
const metadataFilter = { priority: 'MEDIUM' };
performFilteredVectorSearch(text, metadataFilter);
The above function, when executed, will list five rows from the table whose vectors are semantically similar to the vector embedding generated from text, filtered by the priority field.
Note that the above SQL query uses L2 Distance (Euclidean Distance) metric to perform the similarity search, represented by the <-> operator.
In pgvector, you can modify the similarity search algorithm simply by changing the operator in the query. Here are the other similarity metrics you can use:
- Cosine similarity: represented by
<=>operator - Inner product: represented by
<#>operator
Similarly, you can also use other metadata filters along with your similarity search to narrow down your search further.
Next Steps
We demonstrated how you can build high-performance, efficient search systems by leveraging PostgreSQL with pgvector, pgai, and pgvectorscale, along with JavaScript/TypeScript. The advanced indexing techniques provided by pgvectorscale ensure that your search infrastructure is both cost-effective and scalable.
Start implementing your own filtered semantic search today to unlock the full potential of your data. To learn more about pgvector, pgvectorscale, and pgai, check out the references below:



